Where do Mayors Come From: Querying Wikidata with Python and SPARQL
01 Aug 2018Table of Contents
- Introducing SPARQL
- Advanced Queries
- SPARQL Data Representation
- Retrieving SPARQL Queries with Python
- Mayors of all European Capitals
- Conclusion
- Resources
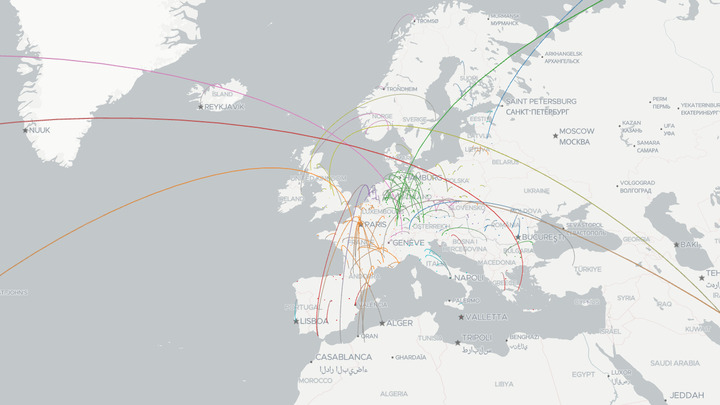
In this article, we will be going through building queries for Wikidata with Python and SPARQL by taking a look where mayors in Europe are born. This tutorial is building up the knowledge to collect the data responsible for this interactive visualization from the header image which was done with deck.gl.
Wikidata is a free and collaborative Linked Open Data (LOD) knowledge base which can be edited by humans and machines. The project started 2012 by the Wikimedia Foundation as an effort to centralize interwiki links, infoboxes and enable rich queries. Its ambitious goal is to structure the whole human knowledge in a way that is machine readable and it speaks well to the vision of Tim Berners-Lee in his TED talk of 2009. Surprisingly, the idea of the Semantic Web existed already in 2001 which is comprised of Linked Data. There have been many projects preceding Wikidata. There is DBpedia which is based on the infoboxes in Wikipedia, Friend of a Friend (FOAF) which is an ontology to describe relationships in social networks, GeoNames which provides a database with geographical names, Upper Mapping and Binding Exchange Layer (UMBEL) which is a knowledge graph of concepts and entities and a whole set of others, but Wikidata seems to be the most ambitious project between them.
All of the data there is free (under the CC0 1.0 aka public domain), while anyone can edit and contribute to it. So it works in a similar way to Wikipedia. On most (if not all) Wikipedia pages, there is a Wikidata Item link to its corresponding item in Wikidata, where you can find the linked information listed. Note that you can still find holes, but as it is a community effort, this is becoming better and growing over time by every contribution. To access the structured data you can query Wikidata by using its SPARQL endpoint which enables you to run advanced queries, or by using its REST API.
In this diagram, you can see the structure of a Wikidata item. Each item has a list of statements, which are triples in the form SUBJECT - PREDICATE - OBJECT (e.g. Douglas Adams is educated at the St John’s College). In Wikidata the subject is referred to as item and the predicate is referred to as property. Each property has a value, which can be again an item, text, number, date, or GPS coordinates among others. Each value can have additional qualifiers which have additional information with other property-value pairs such as start time. This structure will be important when we start to express queries with SPARQL.
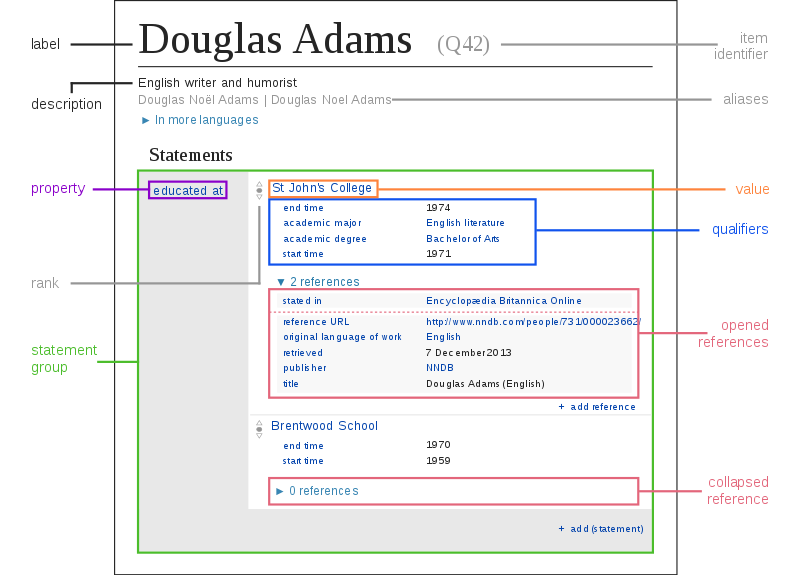
image from SPARQL/WIKIDATA Qualifiers, References and Ranks.
Also, all the code for this article and the interactive visualization can be found in this repository.
Introducing SPARQL
Before getting to Python we will dissect SPARQL to get comfortable doing some queries. SPARQL is a query language used to retrieve data stored as RDF (Resource Description Framework) and it is standardized by the W3C. It is a powerful language to query Linked data and we can also use it to query Wikidata. The syntax is similar to SQL, but it has some differences for people trained in SQL. One key difference is that in SQL you tend to avoid JOIN clauses as they can slow down queries, but in SPARQL the queries mostly consist of joins. But hang in there and let’s take a look at such a query. In this example, we want to list all countries in the European Union.
SELECT ?country ?countryLabel WHERE {
?country wdt:P463 wd:Q458.
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
You can try this query yourself here. Note that you can test and play with each query at https://query.wikidata.org/. The editor there offers a handful of useful features. If you hover over the properties and items in the editor you will get information about them and the editor additionally offers autocompletion. You will also find a list of examples which are quite handy when starting fresh.
Starting with the SELECT clause, we define the variables we want to get (variables are prefixed with a question mark). Inside the WHERE clause, we set restrictions which mostly take the form of the triples we have covered previously. The statement ?country wdt:P463 wd:Q458. collects all items which have the property member of (P463) with object European Union (Q458) into the variable country. As you can see, the statements read like a sentence (i.e. country is a member of the European Union). You also notice that there are the prefixes wd: and wdt:. These denote items with wd: and properties with wdt:. We will cover more complicated prefixes later on in this tutorial when we will get into the SPARQL data representation.
Finally, you will see a confusing part SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } within the query. This snippet is responsible for retrieving labels for the collected items into an additional variable with Label postfix in the specified language (in this case English). In this query, this would be the countryLabel variable storing the label for the country variable. Note that the label is only retrieved for items that have a label in the particular language selected (in this case "en" for English), as there might be items that are not translated into this particular language.
Interesting sidenote: When running the query you will notice Kingdom of the Netherlands with Wikidata item Q29999 in the list of European countries. Surprisingly, Netherlands (Q55) is a constituent country of the Kingdom of the Netherlands, but it is not a country. It is similar to how England is part of the United Kingdom. This video does a great job explaining the situation if you were puzzled.
Advanced Queries
Let’s now explore other properties of the countries we have selected. If you take a look at Germany (Q183), then you can see a whole host of properties like population (P1082), median income (P3529) or even images with the image (P18) property. SPARQL enables us to retrieve those too which leads us to the next query.
SELECT
?country ?countryLabel ?population ?area ?medianIncome
WHERE {
?country wdt:P463 wd:Q458.
?country wdt:P1082 ?population.
?country wdt:P2046 ?area.
?country wdt:P3529 ?medianIncome.
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
You can try this query here.
After trying this query you will notice that the list of countries became shorter. The reason for this is that each country item that has no population, area or median income as a property is ignored by the query. You can imagine those triples also as a filter constraining the triples that only match this query. We can add the OPTIONAL clause which will leave those variables empty if the query cannot find triples within this clause.
SELECT
?country ?countryLabel ?population ?area ?medianIncome
WHERE {
?country wdt:P463 wd:Q458.
OPTIONAL { ?country wdt:P1082 ?population }
OPTIONAL { ?country wdt:P2046 ?area }
OPTIONAL { ?country wdt:P3529 ?medianIncome }
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
You can try this query here. Now we see in the table that we will find all countries again.
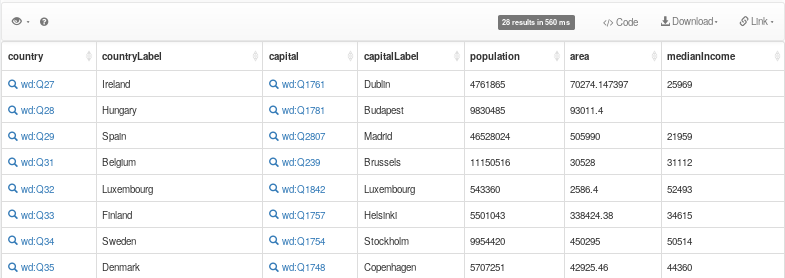
SPARQL Data Representation
We continue our journey with a complicated query which we will unpack step by step. Our goal is now to get for all countries, the capital, the population, the mayor, his birthday and finally his birthplace. The query looks like this.
SELECT DISTINCT
?country ?countryLabel ?capital ?capitalLabel ?population
?mayor ?mayorLabel ?birth_place ?birth_placeLabel ?birth_date ?age
WHERE {
# Get all european countries, their capitals and the population of the capital
?country wdt:P463 wd:Q458.
?country wdt:P36 ?capital.
OPTIONAL { ?capital wdt:P1082 ?population. }
# Get all mayors without an end date
?capital p:P6 ?statement.
?statement ps:P6 ?mayor.
FILTER NOT EXISTS { ?statement pq:P582 ?end_date }
# Get birth place, birth date and age of mayor
?mayor wdt:P19 ?birth_place.
?mayor wdt:P569 ?birth_date.
BIND(year(now()) - year(?birth_date) AS ?age)
SERVICE wikibase:label {
bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en".
}
}
You can try this query here.
Let’s unpack what is happening here. First, we start by getting the capital of the country which we simply get via the capital (P36) property. Next, we get to a more complicated part. To understand how to get to the mayor we have to look at the SPARQL Data Representation in this diagram.
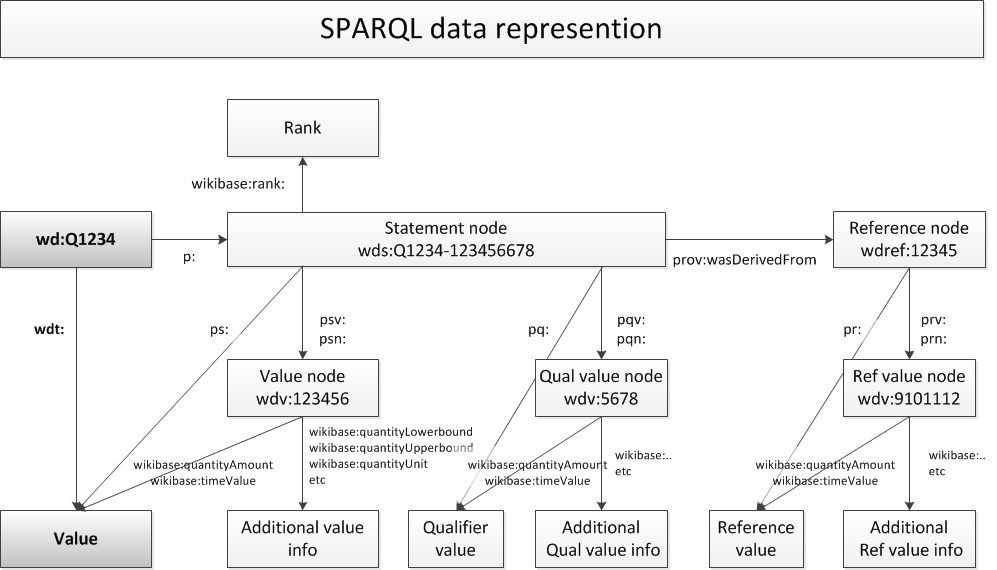
image from SPARQL/WIKIDATA Qualifiers, References and Ranks.
This graph of the data representation that you see here shows the ways you can traverse it to get to various pieces of information with SPARQL starting from an item (in the graph shown as wd:Q1234). You can see on the left the classical path we took in our previous triples by using the wdt: prefix which leads to the value which can be another item, a numeric value (e.g. the population as in one of the previous queries) or various other data types.
If you take a look at an item like Rome (Q220), you will notice that there are various statements for the head of government (P6). We want to get the one which has no end date. We can do this by traversing to the statement node with the p: prefix and storing it in the statement variable. From this variable, we can get the mayor with the ps: prefix. We could have done that with wdt: as we already have learned but we want to go one step further. We want to get to end time (P582) which is stored as a qualifier in the statement. We can traverse to the qualifier with the pq: prefix which would give us the end date, but we want mayors without an end date. This can be done by using the FILTER NOT EXISTS clause which excludes all triples with statement node that have an end date.
In the final part, we collect the birthplace, the birth date and the age of the mayor. In order to calculate his age, we use the BIND expression. This expression can be used to bind some expression to a variable (in our case the age variable). For this expression, we subtract the year of the birth date with the current year. This concludes this query. You can dig deeper in SPARQL/WIKIDATA Qualifiers, References and Ranks which describes the data representation in further detail.
Retrieving SPARQL Queries with Python
We have seen how to work with SPARQL and we can also download the resulting tables in the editor, but how do we automate the whole process? We can access the Wikidata SPARQL endpoint also with Python, which enables us to directly load and analyze the data we have queried. To do this, we will employ the request module which does a great job at doing HTTP requests with all its necessary tooling. We can create the request by adding the query as a parameter as follows.
import requests
url = 'https://query.wikidata.org/sparql'
query = """
SELECT
?countryLabel ?population ?area ?medianIncome ?age
WHERE {
?country wdt:P463 wd:Q458.
OPTIONAL { ?country wdt:P1082 ?population }
OPTIONAL { ?country wdt:P2046 ?area }
OPTIONAL { ?country wdt:P3529 ?medianIncome }
OPTIONAL { ?country wdt:P571 ?inception.
BIND(year(now()) - year(?inception) AS ?age)
}
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
"""
r = requests.get(url, params = {'format': 'json', 'query': query})
data = r.json()
We have packed the query in the query variable and we need to additionally supply request with the SPARQL endpoint URL which is https://query.wikidata.org/sparql. We want to use JSON as an output file, so we add this also to our request. The API returns XML as default but supports besides JSON also TSV, CSV and Binary RDF. This request returns a JSON with all the rows collected from the query, which we can use collect the rows into a Pandas DataFrame as follows.
import pandas as pd
from collections import OrderedDict
countries = []
for item in data['results']['bindings']:
countries.append(OrderedDict({
'country': item['countryLabel']['value'],
'population': item['population']['value'],
'area': item['area']['value']
if 'area' in item else None,
'medianIncome': item['medianIncome']['value']
if 'medianIncome' in item else None,
'age': item['age']['value']
if 'age' in item else None}))
df = pd.DataFrame(countries)
df.set_index('country', inplace=True)
df = df.astype({'population': float, 'area': float, 'medianIncome': float, 'age': float})
df.head()
| population | area | medianIncome | age | |
|---|---|---|---|---|
| country | ||||
| Kingdom of the Netherlands | 17100715.0 | NaN | NaN | 203.0 |
| Ireland | 4761865.0 | 70274.147397 | 25969.0 | 81.0 |
| Belgium | 11150516.0 | 30528.000000 | 31112.0 | 188.0 |
| Hungary | 9830485.0 | 93011.400000 | NaN | 1018.0 |
| Spain | 46528024.0 | 505990.000000 | 21959.0 | 539.0 |
Let’s explore the collected data visually and compare the various properties for each country.
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(16, 12))
for i, label in enumerate(['population', 'medianIncome', 'area', 'age']):
plt.subplot(2, 2, i + 1)
df_plot = df[label].sort_values().dropna()
df_plot.plot(kind='barh', color='C0', ax=plt.gca());
plt.ylabel('')
plt.xticks(rotation=30)
plt.title(label.capitalize())
plt.ticklabel_format(style='plain', axis='x')
plt.tight_layout()
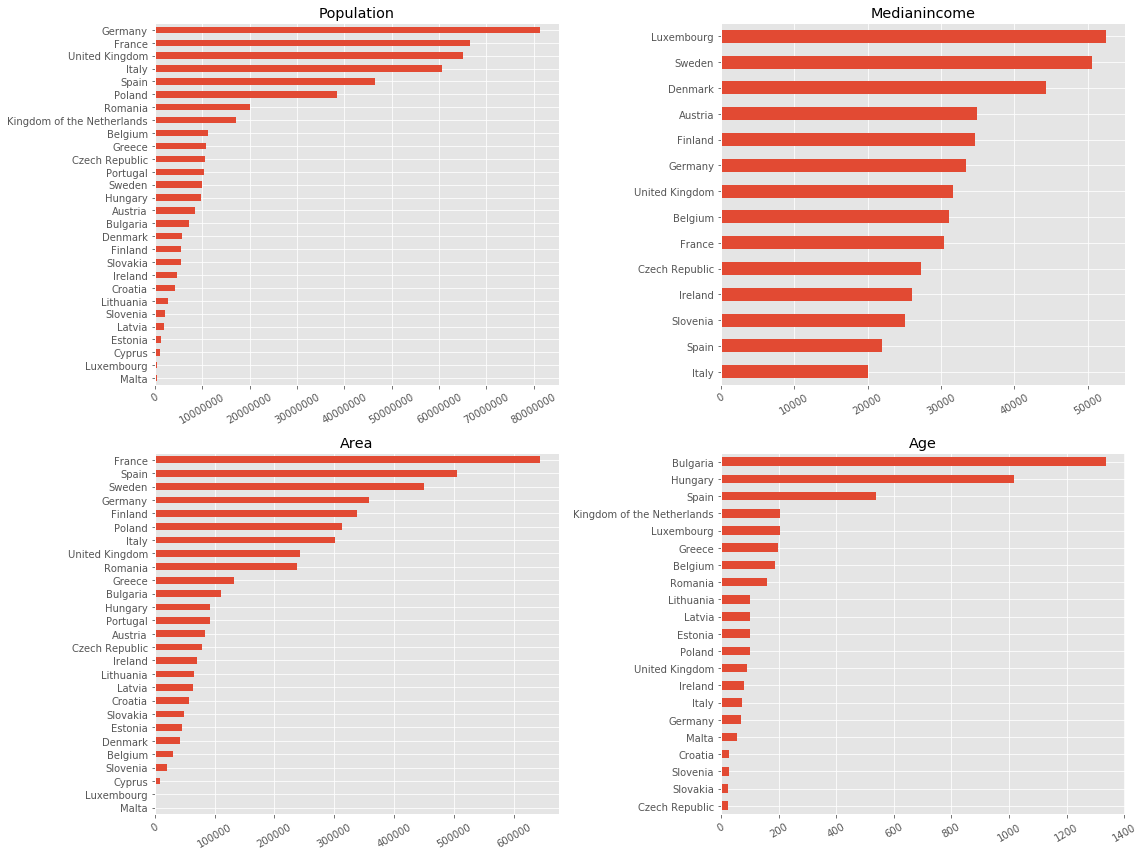
Mayors of all European Capitals
In our final query, we will take a look at where mayors are born by adding the coordinates to the query. In order to get the latitude and longitude coordinates as variables, we need to add the following snippet.
?capital p:P625/psv:P625 ?capital_node.
?capital_node wikibase:geoLatitude ?capital_lat.
?capital_node wikibase:geoLongitude ?capital_lon.
In the first line, we traverse the graph of the previously shown data representation. The slash in p:P625/psv:P625 means that we continue to the Value node of the coordinate location (P625) without using a separate variable for the Statement node. Then, wikibase:geoLatitude and wikibase:geoLongitude are responsible for retrieving the latitude and longitude from the Value node respectively. For more information, take a look at Precision, Units and Coordinates.
url = 'https://query.wikidata.org/sparql'
query="""
SELECT DISTINCT
?countryLabel ?capitalLabel ?population ?capital_lon ?capital_lat
?mayorLabel ?birth_date ?age ?birth_place ?birth_placeLabel ?birth_place_lon ?birth_place_lat
WHERE {
?country wdt:P463 wd:Q458.
?country wdt:P36 ?capital.
OPTIONAL { ?capital wdt:P1082 ?population. }
# Get latitude longitude coordinates of capital
?capital p:P625/psv:P625 ?capital_node.
?capital_node wikibase:geoLatitude ?capital_lat.
?capital_node wikibase:geoLongitude ?capital_lon.
?capital p:P6 ?statement.
?statement ps:P6 ?mayor.
FILTER NOT EXISTS { ?statement pq:P582 ?end_date }
?mayor wdt:P569 ?birth_date.
BIND(year(now()) - year(?birth_date) AS ?age)
?mayor wdt:P19 ?birth_place.
?birth_place wdt:P625 ?birth_place_coordinates.
# Get latitude longitude coordinates of birth place
?birth_place p:P625/psv:P625 ?birth_place_node.
?birth_place_node wikibase:geoLatitude ?birth_place_lat.
?birth_place_node wikibase:geoLongitude ?birth_place_lon.
SERVICE wikibase:label {
bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en".
}
}
"""
r = requests.get(url, params = {'format': 'json', 'query': query})
data = r.json()
countries = []
for item in data['results']['bindings']:
countries.append(OrderedDict({
label : item[label]['value'] if label in item else None
for label in ['countryLabel', 'capitalLabel', 'capital_lon', 'capital_lat', 'population',
'mayorLabel', 'birth_date', 'age',
'birth_placeLabel', 'birth_place_lon', 'birth_place_lat']}))
df = pd.DataFrame(countries)
df.set_index('capitalLabel', inplace=True)
df = df.astype({'population': float, 'age': float,
'capital_lon': float, 'capital_lat': float,
'birth_place_lon': float, 'birth_place_lat': float})
df.head()
| countryLabel | capital_lon | capital_lat | population | mayorLabel | birth_date | age | birth_placeLabel | birth_place_lon | birth_place_lat | |
|---|---|---|---|---|---|---|---|---|---|---|
| capitalLabel | ||||||||||
| Tallinn | Estonia | 24.745000 | 59.437222 | 446055.0 | Taavi Aas | 1966-01-10T00:00:00Z | 52.0 | Tallinn | 24.745000 | 59.437222 |
| Brussels | Belgium | 4.354700 | 50.846700 | 176545.0 | Philippe Close | 1971-03-18T00:00:00Z | 47.0 | Namur | 4.866667 | 50.466667 |
| Sofia | Bulgaria | 23.333333 | 42.700000 | 1286383.0 | Yordanka Fandakova | 1962-04-12T00:00:00Z | 56.0 | Samokov | 23.560000 | 42.338056 |
| Warsaw | Poland | 21.033333 | 52.216667 | 1753977.0 | Hanna Gronkiewicz-Waltz | 1952-11-04T00:00:00Z | 66.0 | Warsaw | 21.033333 | 52.216667 |
| Stockholm | Sweden | 18.068611 | 59.329444 | 935619.0 | Karin Wanngård | 1975-06-29T00:00:00Z | 43.0 | Ekerö | 17.799879 | 59.274446 |
Taking this data set we can explore the age of the mayors and the population of the capital they are serving.
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
df['age'].sort_values().plot(kind='barh', color='C0', title='Mayors Age')
plt.ylabel('')
plt.subplot(1, 2, 2)
df['population'].sort_values().plot(kind='barh', color='C0', title='Population')
plt.ylabel('')
plt.ticklabel_format(style='plain', axis='x')
plt.tight_layout()
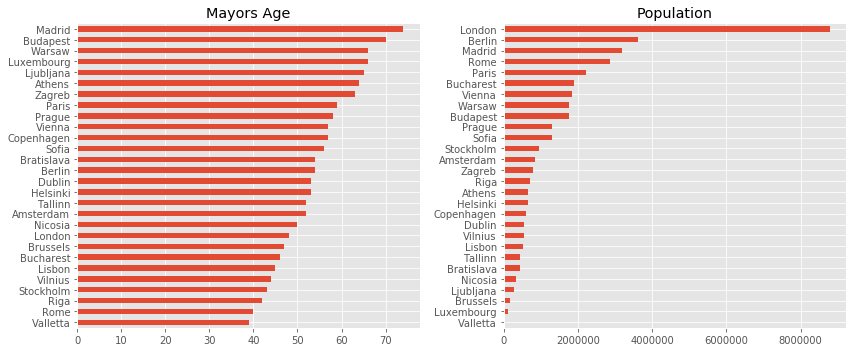
Next, let’s take a look at how far mayors are born from the capital. For this, we will use the geopy package to calculate the distance between the coordinates. This tutorial covers this topic if you are curious why we can’t just use euclidean distance on GPS coordinates.
from geopy.distance import distance
coordinates = df[['capital_lon', 'capital_lat', 'birth_place_lon', 'birth_place_lat']]
df['distance'] = [distance((lat0, lon0), (lat1, lon1)).m
for lon0, lat0, lon1, lat1 in coordinates.values]
df['distance'].sort_values().plot(kind='barh', color='C0', logx=True, figsize=(12, 7))
plt.xlabel('Distance (m)')
plt.ylabel('');
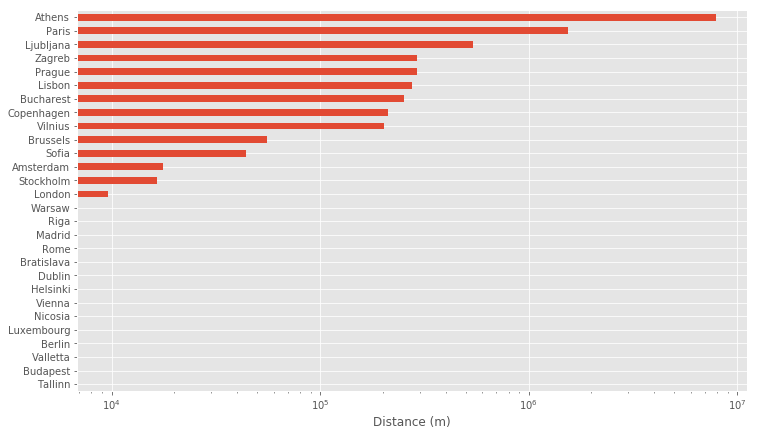
Here we can see that most mayors tend to be born in or close to the city where they later serve (note, that the chart is in log-scale). We can see that Athens leads the exceptions with their current mayor (Giorgos Kaminis) born in New York, USA and Paris with their current mayor (Anne Hidalgo) born in San Fernando, Spain. From there the distances drop significantly.
To get a list of all mayors in Europe, take a look at this script, which is more involved as it has to deal with some exceptions (like mayors born in countries that do not exist anymore) and the queries need to be done for each country separately because there is a limit on the queries. The final interactive visualization can be found here and the complete code including this notebook can be found in this repository.
Conclusion
We have learned how to work with Wikidata and SPARQL and also how to integrate it with Python and Pandas. Wikidata is a great database that enables queries and discoveries that would not be possible with ordinary searches on your favorite search engine. This opens up exciting new possibilities to do data science and exploratory data analysis and a fascinating new way to learn about relationships and curious findings in our accumulated human knowledge.
Resources
A good read covering the history and an overview of Wikidata can be found in the article Wikidata: a free collaborative knowledge base. by Vrandečić, D., & Krötzsch, M. (2014). There is a great SPARQL tutorial covering many of the things mentioned here and goes into much more depth into understanding SPARQL. If you are excited about Wikidata and want to contribute, there are Wikidata Tours that can guide you through the process. If you plan on doing large queries, make sure to take a look at the publicly downloadable Wikidata dumps which are regularly updated dumps of the whole Wikidata data set and here is a documentation on the Wikibase data model. Wikidata provides also a list of Tools for programmers.
Here is an unstructured list of resources that contain useful documentation, tutorials or examples that use Wikidata. If you are aware of more useful resources or if you generally have some feedback feel free to contact me or add a push request to the notebook of this article.
- Wikidata:List of properties
- Wikidata:Database reports
- Wikidata:Database reports/List of properties/Top100
- Wikidata:Introduction
- Wikidata:SPARQL queries
- Wikidata:SPARQL queries examples
- Wikidata:Creating a bot
- Querying Wikidata About Vienna’s Tram Lines: An Introduction to SPARQL
- How US Presidents Died According to Wikidata
- An Ambitious Wikidata Tutorial - SlideShare
- Wikidata Graph Builder, great tool to visualize Wikidata graphs
- Histropedia, visualization of historical timelines