 Image from Wikimedia Commons
Image from Wikimedia Commons
{kind=link}
How to Install Presto or Trino on a Cluster and Query Distributed Data on Apache Hive and HDFS
17 Oct 2020Table of Contents
- Installation
- Configuration
- Logging in Trino
- Hive Connector
- Start Trino
- Command Line Interface
- Conclusion
Presto is an open source distibruted query engine built for Big Data enabling high performance SQL access to a large variety of data sources including HDFS, PostgreSQL, MySQL, Cassandra, MongoDB, Elasticsearch and Kafka among others.
Update 6 Feb 2021: PrestoSQL is now rebranded as Trino. Read more about it here. If you installed PrestoSQL before, have a look at the migration guide. This tutorial was done using PrestoDB 0.242 and PrestoSQL 344.
To start off with a bit of history: Presto started 2012 in Facebook and was later released in 2013 as an open source project under the Apache Licence. It is most comparable to Apache Spark in the Big Data space as it also offers query optimization with the Catalyst Optimizer and an SQL interface to its data sources. Presto and Apache Spark have its own resource manager, but Apache Spark is generally run on top of Hadoops’ YARN resource manager. Presto on the other hand uses its own coordinator within the cluster to schedule queries among its workers.
Presto itself does not offer a database and should be only used for large analytical queries that fall into Online Analytical Processing (OLAP). Therefore Online transaction processing (OLTP) workloads should be avoided. Presto offers a large variety of connectors like for example MySQL, PostgreSQL, HDFS with Hive, Cassandra, Redis, Kafka, ElasticSearch, MongoDB among others. Further, Presto enables federated queries which means that you can query different databases with different schemas in the same SQL statement at the same time.
To read further into the inner workings and architecture behind Presto, check out the 2019 paper Presto: SQL on Everything.
Installation
Prerequesite for this tutorial is having a running Hadoop and Hive installation, you can follow the instructions in the tutorial How to Install and Set Up a 3-Node Hadoop Cluster and this Hive Tutorial. The configuration and setup scripts used for this tutorial including further configurations of the HDFS cluster can be found in this repository. This installation also requires Java version >= 11. To install Java you can type:
sudo apt-get update
sudo apt-get install openjdk-11-jdk-headless \
openjdk-11-jre-headless \
openjdk-11-jre
Note, that there are two active projects of Presto, Trino and PrestoDB. To clarify the difference between both, have a read into What is the relationship of prestosql and prestodb?. All of this article including the configuration runs on both with the releases of presto-server 0.242 and trino-server 352. In this article we will focus on Trino. First, download Trino and unpack it to a desired location. In this case it will be located in /usr/local/trino.
wget "https://repo1.maven.org/maven2/io/trino/trino-server/352/trino-server-352.tar.gz"
tar -xzvf trino-server-352.tar.gz
sudo mv trino-server-352 /usr/local/trino
sudo chown $USER:$USER /usr/local/trino
Next, add TRINO_HOME environment variable and add the TRINO_HOME/bin directory to the PATH environment variable in ~/.bashrc:
export TRINO_HOME=/usr/local/trino
export PATH=$PATH:$TRINO_HOME/bin
If you aim to run multiple servers, this needs to be done for all servers.
Configuration
Before being able to start Presto, you need to to configure Presto on your system. For this you will need to add the following files:
etc/node.propertiesetc/jvm.configetc/config.propertiesetc/log.propertiesetc/catalog/hive.properties
Let’s start by creating the etc folder where all these files will be located:
mkdir /usr/local/presto/etc
Now, create a node properties file etc/node.properties with the contents:
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/usr/local/presto/data
Each server needs a unique node.id. For this, you can generate a UUID with Python, by typing python -c "import uuid; print(uuid.uuid1())" Another way is to install the uuid package with sudo apt install uuid and then typing uuid. Next, create JVM config file etc/jvm.config with the contents:
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-Djdk.attach.allowAttachSelf=true
It is important to set the flag -Xmx16G to the available RAM on the nodes (in this case 16 GB). A rule of thumb is to allocate around 80% of the available RAM to leave some for the operating system and other processes. The flag -Djdk.attach.allowAttachSelf=true needs to be added in order to avoid the error Error injecting constructor, java.io.IOException: Can not attach to current VM. These two files (except the node.id) are the same for all servers.
Single Node
Create config properties file etc/config.properties with the contents:
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
query.max-memory=5GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://master-node:8080
The discovery.uri specifies the URI of the discovery server. This is generally the same server where the coordinator is located, so take the host and port of this server.
Multiple Nodes
Configuration for the coordinator is the following:
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://master-node.net:8080
If the coordinator should be also used to compute queries set node-scheduler.include-coordinator=true.
Configuration for the workers:
coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
discovery.uri=http://master-node.net:8080
Some more points and the various properties are covered in the documentation on Deploying Presto
Logging in Trino
Create log configuration file etc/log.properties with the following contents:
io.trino=DEBUG
The log levels are DEBUG, INFO, WARN and ERROR, default is INFO. By default, the log files are located in data/var/log and are generally helpful when searching for issues with failed Presto queries or crashed Presto nodes. Additionally, Presto offers a JMX Connector to monitor and debug Java Management Extensions (JMX) information from all nodes.
Hive Connector
In order to connect to HDFS, we will use Apache Hive, which is commonly used together with Hadoop and HDFS to provide an SQL-like interface. Apache Hive was open sourced 2008, again by Facebook. Presto was later designed to further scale operations and reduce query time. Presto and the Hive connector do not use the Hive runtime, but rather act as a replacement in order to run interactive queries.
Add the Hive connector by adding the configuring the connection with etc/catalog/hive.properties with the following contents (port 9083 by default):
connector.name=hive-hadoop2
hive.metastore.uri=thrift://localhost:9083
For more information have a look at the documentation for the Hive Connector. Start the HiveServer2 if it is not already running with:
hive \
--service hiveserver2 \
--hiveconf hive.server2.thrift.port=9083
Start the command-line interface of Hive with Beeline and create a schema that we use for our data with:
CREATE SCHEMA tutorial;
USE tutorial;
Here, we will use the often used and abused Iris Data Set. After downloading the data set, create a table for our data with:
DROP TABLE IF EXISTS tutorial.iris;
CREATE TABLE tutorial.iris (
sepal_length FLOAT,
sepal_width FLOAT,
petal_length FLOAT,
petal_width FLOAT,
class STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
Then, insert the downloaded data to Hive with:
LOAD DATA LOCAL INPATH '/path/to/data/iris.data'
OVERWRITE INTO TABLE tutorial.iris;
To see the freshly create table type SHOW TABLES tutorial;. To show metadata about a table such as column names and their data types, you can type DESCRIBE tutorial.iris; which should return the following output:
+---------------+------------+----------+--+
| col_name | data_type | comment |
+---------------+------------+----------+--+
| sepal_length | float | |
| sepal_width | float | |
| petal_length | float | |
| petal_width | float | |
| class | string | |
+---------------+------------+----------+--+
5 rows selected (2 seconds)
For even more information you can use DESCRIBE FORMATTED tutorial.iris;.
The Hive connector is also used with the various cloud-based object stores like S3, GCS, Azure Blob Storage, Minio and others. To read more on this have a read in this explainer.
Start Trino
Now, everything is set to start Presto. To start the Presto daemon simply run on each node:
launcher start
The status of the daemon and its PID can be checked with:
launcher status
The deamon can be stopped with:
launcher stop
The server can be accessed at http://localhost:8080, which was previously configured in etc/config.properties. This would give you an overview of the cluster and statistics on the queries that have been run:
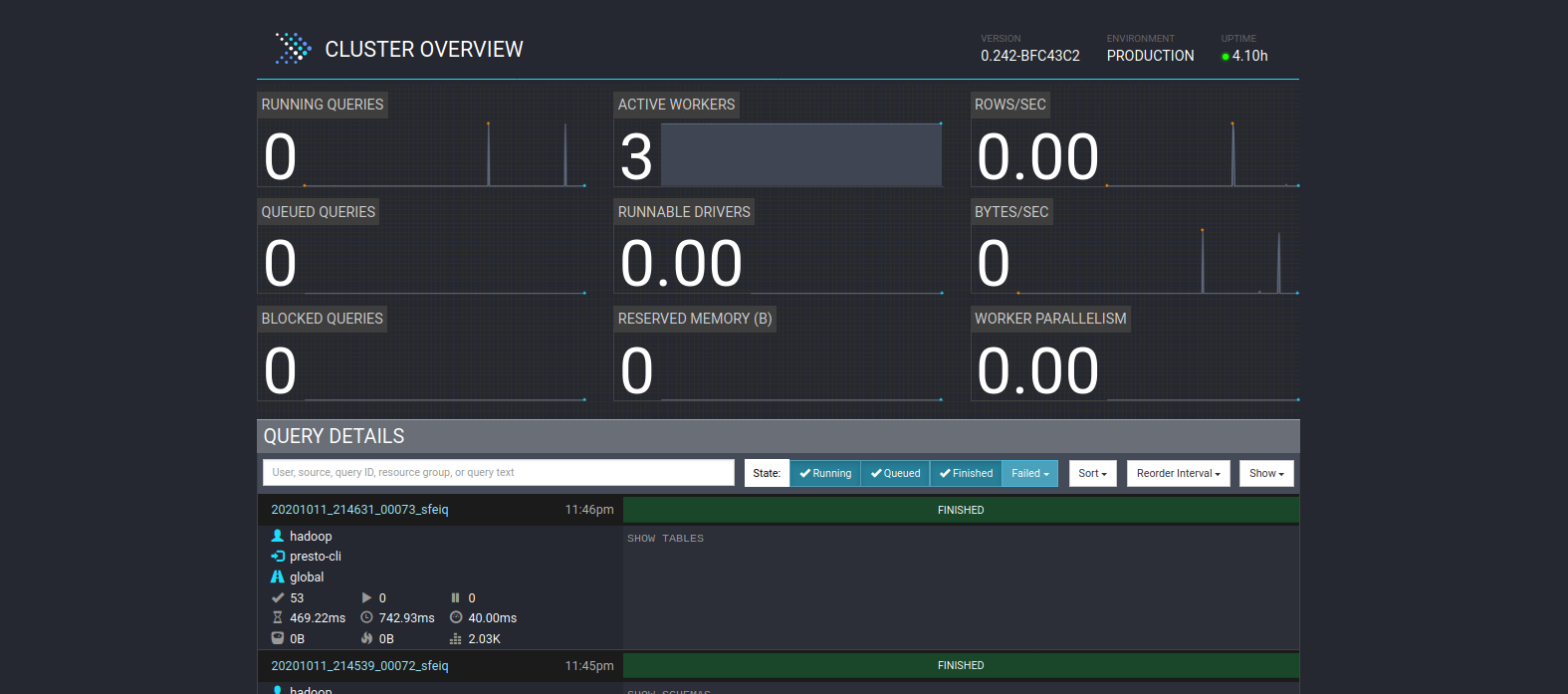
Command Line Interface
Presto does not install the command-line by default, therefore we need to download the command-line interface separately:
wget "https://repo1.maven.org/maven2/io/prestosql/presto-cli/344/\
presto-cli-344-executable.jar"
mv presto-cli-344-executable.jar /usr/local/presto/bin/presto
chmod +x /usr/local/presto/bin/presto
Start the Presto CLI for Hive catalog with the previously created tutorial schema:
presto \
--catalog hive \
--schema tutorial
Here is the documentation on the Command Line Interface. Instead of using the Presto command-line interface, you can also use DBeaver which offers a Presto connection via Java Database Connectivity (JDBC). Somewhat similar to Hive you can list all available Hive schemas with:
SHOW SCHEMAS FROM hive;
To list all the available tables from a Hive schema, type:
SHOW TABLES FROM hive.tutorials;
Now, let’s try querying the data we previously added. Here we answer the question: What is the average sepal length and width per iris class:
SELECT
class,
AVG(sepal_length) AS avg_sepal_length,
AVG(sepal_width) AS avg_sepal_width
FROM tutorial.iris
GROUP BY class;
Which should return the following output:
class | avg_sepal_length | avg_sepal_width
-----------------+------------------+-----------------
Iris-versicolor | 5.936 | 2.77
Iris-setosa | 5.006 | 3.418
Iris-virginica | 6.588 | 2.974
(3 rows)
That’s nice, we can already see clear differences here between the flowers without resorting to deep learning. Also note that Presto uses the ANSI SQL Dialect. To read more about the SQL Syntax in Presto have a look at the documentation on SQL Statement Syntax and to analyze the execution plan, you can use EXPLAIN or EXPLAIN ANALZE in front of a statement or explore the Live Plan for a query in the Presto UI.
Conclusion
For more information have a look at the paper Presto: SQL on Everything, which explains the inner workings of Presto in much more technical detail and also explains some of the challenges that Presto tries to solve. Additionally there is Presto: The Definitive Guide, a great book that goes into much more detail on how to use and configure Presto in an optimal way.
Further resources and links are listed in the homepage of the Presto Software Foundation. It is also helpful to directly check the issues and pull requests in the prestodb/presto and prestosql/presto Github pages as they often include detailed descriptions of some of the more advanced features. Finally, Mark Litwintischik did a great performance comparision of Spark 2.4.0 versus Presto 0.214.